
漢德百科全書 | 汉德百科全书
 IT-Times
IT-Times



Einblicke in technologische Durchbrüche

Einheitliche KI-Architektur
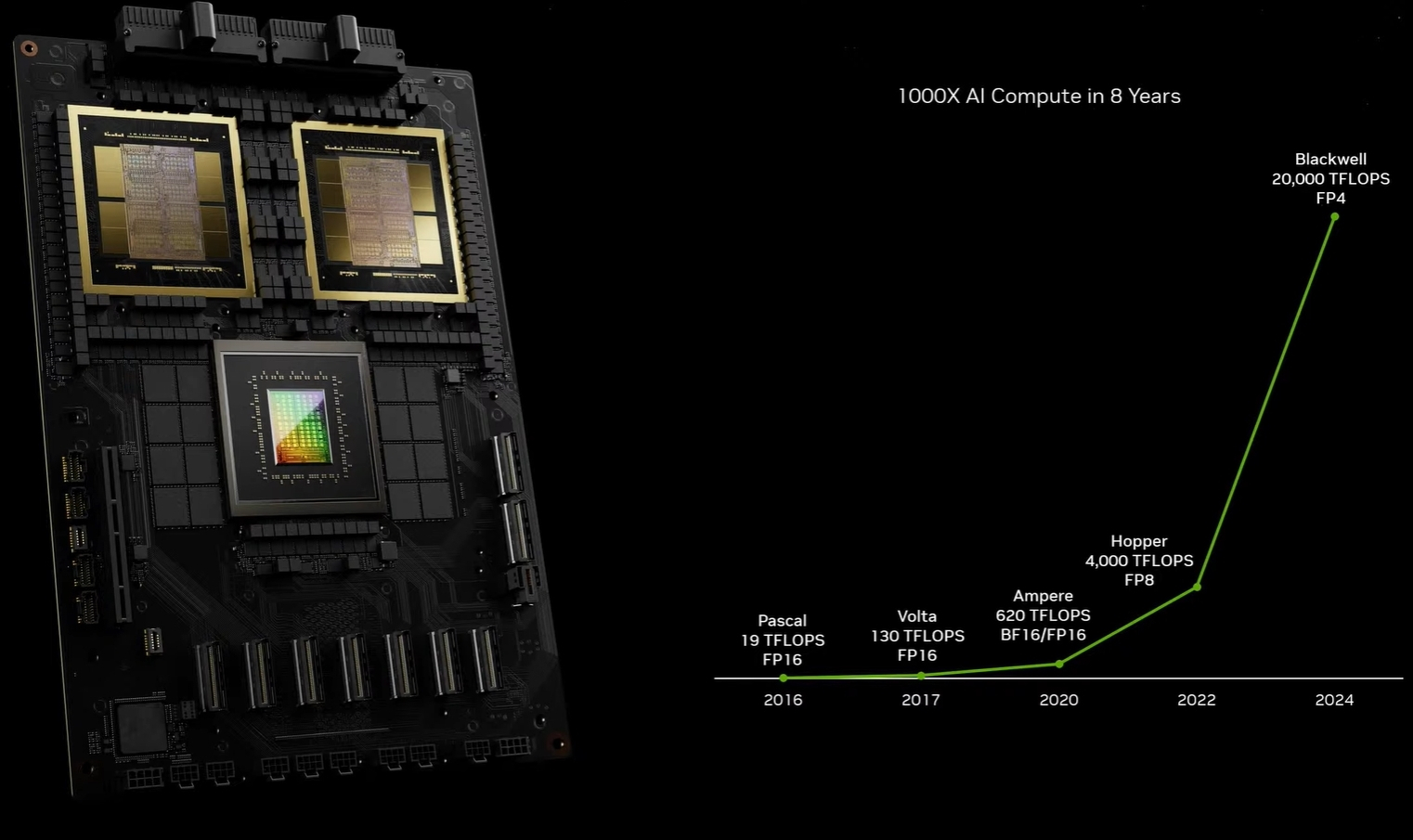
Blackwell besteht aus 208 Milliarden Transistoren mit einem TSMC-4NP-Prozess, der den Erwartungen an die Führungsrolle von NVIDIA im Bereich beschleunigte Berechnungen entspricht, und seine Grafikprozessoren sind die leistungsstärksten Chips, die jemals entwickelt wurden. Die beiden Dies sind so groß wie möglich. Sie bieten die schnellste Kommunikationsleistung für KI-Operationen und maximieren gleichzeitig die Energieeffizienz. Sie sind über eine Chip-zu-Chip-NVHyperfuse-Schnittstelle miteinander verbunden, die 10 Terabyte pro Sekunde (TB/s) unterstützt. So wird eine transparente Einzel-GPU-Ansicht für alle Caches und Kommunikation möglich.
Generative KI-Engine
Außer der Transformer Engine-Technologie, die Training mit der Präzision von FP8 und FP16 beschleunigt, wird mit Blackwell die neue generative KI-Engine eingeführt. Die generative KI-Engine nutzt die angepasste Blackwell Tensor Core-Technologie zur Beschleunigung der Inferenz für generative KI und große Sprachmodelle (LLMs) mit neuen auf Präzision fokussierten Formaten, einschließlich Community-definierter Microscaling(MX)-Formate. Die Formate MXFP4, MXFP6, MXFP8 und MXINT8 der generativen KI-Engine bieten eine enorme Beschleunigung für moderne LLMs mit verbesserter Leistung durch geringeren Platzbedarf und mehr Durchsatz als FP8 und FP16.


Sichere KI
LLMs bergen ein enormes Potenzial für Unternehmen. Die Umsatzoptimierung, die Bereitstellung von Geschäftsinformationen und die Unterstützung bei der Erstellung generativer Inhalte sind nur einige der Vorteile. Doch die Einführung von LLMs kann für Unternehmen schwierig sein, da sie sie schulen müssen und dafür private Daten verwenden, die entweder Datenschutzbestimmungen unterliegen oder proprietäre Informationen enthalten, deren Offenlegung Risiken birgt. Blackwell umfasst NVIDIA Confidential Computing, das mit starker hardwarebasierter Sicherheit vertrauliche Daten und KI-Modelle vor unbefugtem Zugriff schützt.
Erfahren Sie mehr über Confidential Computing von NVIDIA
NVLink, NVSwitch und NVLink-Switch-Systeme
Um das volle Potenzial von Exascale-Computing und KI-Modellen mit Billionen Parametern auszuschöpfen, ist eine schnelle, nahtlose Kommunikation zwischen allen Grafikprozessoren innerhalb eines Server-Clusters erforderlich. Die fünfte Generation von NVLink ist eine Scale-up-Verbindung, die beschleunigte Leistung für KI-Modelle mit Billionen oder mehreren Billionen Parametern bietet.
Die vierte Generation von NVIDIA NVSwitch™ ermöglicht 130 TB/s GPU-Bandbreite in einer NVLink-Domäne mit 72 GPUs (NVL72) und bietet viermal mehr Bandbreiteneffizienz mit FP8-Unterstützung von NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)™. Mithilfe von NVSwitch unterstützt das NVIDIA NVLink-Switch-System Cluster mit mehr als einem einzelnen Server bei denselben beeindruckenden Verbindungsgeschwindigkeiten von 1,8 TB/s. Multi-Server-Cluster mit NVLink skalieren die GPU-Kommunikation angepasst an die zunehmende Rechenleistung, sodass NVL72 den 9-fachen GPU-Durchsatz unterstützen kann als ein einzelnes System mit acht GPUs.
Weitere Informationen zu NVIDIA NVLink und NVSwitch


Dekomprimierungs-Engine
Bei Datenanalysen und Datenbank-Workflows wurden die Berechnungen traditionell auf CPUs durchgeführt. Beschleunigte Datenwissenschaft kann die Leistung von durchgängigen Analysen steigern, die Wertschöpfung beschleunigen und gleichzeitig die Kosten senken. Datenbanken, einschließlich Apache Spark, spielen im Bereich Datenanalyse eine entscheidende Rolle bei der Verarbeitung und Analyse großer Datenmengen.
Blackwells Dekomprimierungs-Engine und die Möglichkeit, auf riesige Mengen an Speicher der NVIDIA Grace™-CPU über eine High-Speed-Verbindung von 900 Gigabyte pro Sekunde (GB/s) bidirektionaler Bandbreite zuzugreifen, beschleunigen die gesamte Pipeline von Datenbankabfragen für höchste Leistung bei Datenanalysen und Datenwissenschaft. Dank der Unterstützung der neuesten Komprimierungsformate wie LZ4, Snappy und Deflate ist Blackwell 20-mal schneller als CPUs und 7-mal schneller als NVIDIA H100 Tensor Core-GPUs bei Abfrage-Benchmarks.
RAS-Engine für Zuverlässigkeit, Verfügbarkeit und Wartungsfreundlichkeit
Blackwell bietet intelligente Ausfallsicherheit mit einer dedizierten Engine für Zuverlässigkeit, Verfügbarkeit und Wartungsfreundlichkeit (Reliability, Availability, and Serviceability, RAS), um potenzielle Fehler frühzeitig zu identifizieren und Ausfallzeiten zu minimieren. Die KI-gestützten Funktionen für vorausschauendes Management von NVIDIA überwachen kontinuierlich den allgemeinen Zustand über Tausende von Datenpunkten von Hardware und Software, um die Ursachen für Ausfallzeiten und fehlende Effizienz vorherzusagen und zu eliminieren. Dadurch entsteht eine intelligente Ausfallsicherheit, die Zeit, Energie und Rechenkosten spart.
Die RAS-Engine von NVIDIA bietet detaillierte Diagnoseinformationen, mit denen Problembereiche identifiziert und Wartungsarbeiten geplant werden können. Die RAS-Engine reduziert die Durchlaufzeit, indem sie die Ursachen von Problemen schnell lokalisiert, und minimiert Ausfallzeiten durch eine effektive Problembehebung.


 Automobil
Automobil
1 × Grace-GPU + 2 × Blackwell-GPU = Grace Blackwell
Der offiziell als GB200 Grace Blackwell Superchip vermarktete Hybrid-Lösung basiert auf einer Grace-CPU mit insgesamt 72 ARM Neoverse V2 Prozessorkernen und zwei Blackwell-GPUs sowie bis zu 384 GiByte HBM3e und 480 GiByte LPDDR5X, was in Nvidias hauseigenem NVL72-Supercomputer in äußerst beeindruckenden technischen Spezifikationen resultiert, welche sich wie folgt lesen.
- 36 Nvidia Grace-CPUs
- 2.592 ARM Neoverse V2 Prozessorkerne
- Bis zu 17 Terabyte LPDDR5X-Arbeitsspeicher
- 72 Blackwell-GPUs mit 13,5 Terabyte HBM3e-Speicher
- FP4-Rechenleistung: Bis zu 1.440 PetaFLOPS
- FP8-Rechenleistung: Bis zu 720 PetaFLOPS
- NVLink: Bis zu 130 TB/s an Bandbreite
Da der Nvidia B200 ("Blackwell") aus insgesamt zwei Dies besteht, stehen jedem GB200-Superchip ("Grace Blackwell") somit vier GPU-Dies zur Verfügung, dem neuen Supercomputer NVL72 somit respektive insgesamt 144 Blackwell-Dies.

Der GB200 NVL72 verbindet 36 Grace-CPUs und 72 Blackwell-GPUs in einem Rack-Maßstab. Bei dem GB200 NVL72 handelt es sich um eine Rack-Lösung mit Flüssigkeitskühlung und einer NVLink-Domäne mit 72 Grafikprozessoren, die als einzelner riesiger Grafikprozessor funktioniert und 30-mal schnellere Echtzeit-Inferenz für LLMs mit Billionen Parametern bietet.
Der GB200 Grace Blackwell Superchip ist eine Schlüsselkomponente des NVIDIA GB200 NVL72 und verbindet zwei hochleistungsfähige NVIDIA Blackwell Tensor-Recheneinheiten-Grafikprozessoren und eine NVIDIA Grace-CPU über die NVIDIA® NVLink®-C2C-Verbindung mit den beiden Blackwell-GPUs.

IT-Times
IT-Times
 Verarbeitungseinheiten - CPU, GPU, NPU, APU, TPU, VPU, FPGA, QPU, IPU, PIC
IT-Times
Games-Industrie
IT-Times
Graphics card/Video card
IT-Times
IC
Verarbeitungseinheiten - CPU, GPU, NPU, APU, TPU, VPU, FPGA, QPU, IPU, PIC
IT-Times
Games-Industrie
IT-Times
Graphics card/Video card
IT-Times
IC
 Nvidia
Nvidia




通过跨 NVIDIA Vera CPU、Rubin GPU、NVLink 6 交换机、ConnectX-9 SuperNIC、BlueField-4 DPU 和 Spectrum-6 以太网交换机的极致协同设计,大幅缩短训练时间,降低推理 token 生成成本。
